
デジタルトランスフォーメーションの過程に欠かせないドキュメントのデジタル化。これに使われる、紙の情報をデジタルに取り込むツールは、日本ではAI-OCRなどと呼ばれているが、この呼び方は日本以外では通用しない。グローバルでは、より広い意味を含む単語として「インテリジェント・ドキュメント・プロセッシング (Intelligent Document Processing: IDP)」が使われる。この記事では、IDPの概念と、調査会社エベレストグループにより発表されたIDPベンダーの最新評価について解説する。
インテリジェント・ドキュメント・プロセッシングとは
インテリジェント・ドキュメント・プロセッシング (IDP)は、機械学習や自然言語処理など、人工知能の技術を使ってドキュメントからデータを抽出する処理の事を指す。これはIPA (インテリジェント・プロセス・オートメーション)の一形式に分類される。つまり、高度なRPAの一分野に位置づけられている。この用語はすでに1970年代には使われていたようである。
紙から文字を読み取る技術は光学文字認識 (OCR) と呼ばれるが、紙から意味のあるデータの形で文字を正確に抜き出すには、文字を読み取る以外にも様々な処理や情報が必要になる。たとえば請求書や注文書などのフォームの中では特定の場所に特定の意味を持つデータが文字列や数字で記載されている。これらを意味のある形で正確に抜き出すには、文字がどの部分に含まれていたか、特定の意味をあらわすのに正しい形式になっているか、数字は検算して正しい値になっているか、などを調べる必要がある。
AI-OCRとの違いは?
OCRの技術は1960年代末に郵便ではがきや封筒に書かれた住所データを自動で読み取り仕訳をするために世界的に応用が始まり、1980年代にかけて一般人にも手が届くくらいの価格になり、応用例も確立されていった。英数字の文字認識は、文字の種類も多くなく、せいぜい筆記体/手書きの認識精度を上げるための努力がなされる程度であったが、日本語は漢字など文字のバリエーションが多く単語に切れ目がないなどの理由で、読み取り精度を出すのが英語よりも難しかった。手書き文字ともなるとなおさらである。そのため、英数字の認識では、早々に文字認識自体よりもドキュメントのコンテキストや意味の抽出に関心が移っていたのに対し、日本語ではつい最近、2015年頃からディープラーニングとクラウドのコンピューティング環境を駆使した技術が登場するまで、文字認識精度の向上、特に手書き文字の認識精度が上がらず問題になっていたため、よりOCRにフォーカスした分野名「AI-OCR」になったものと推測される。ちなみに、AI-OCRにおいてもIDPと同様に文字のコンテキストを読み、そこから文字認識の精度を上げたり、意味のあるデータとして抽出することが行われている。そのため、IDPとAI-OCRは本質的には同じ分野を指すと考えられる。
2021年初頭のIDPにおける世界のリーダーは?
IDP市場の調査はいくつかのグローバル調査会社によって行われている。最近の調査では、エベレストグループが4月19日に発表したIDP PEAK Matrixがある※1。この調査では27のベンダーについてビジョンと機能、市場でのインパクトについて比較が行われており、リーダーには6社が選ばれている。
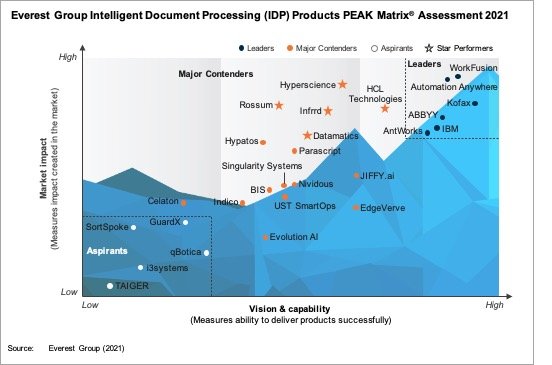
この調査では、WorkFusion、Automation Anywhere、Kofax、ABBYY、IBM、AntWorksがリーダーとして選ばれている。ここで注目したいのは、多くのベンダーはOCRベンダーではなく、RPAベンダーであるということである。
一方、日本市場ではこの分野はAI-OCR市場というふうに呼ばれるが、様相はかなり異なっている。AI-OCR市場のシェア順位はAI Inside、NTT東日本 (AI Inside OEM)、キヤノンITソリューションズであり、いずれもOCR専業が占めている。IDPとAI-OCRの言葉の違いと同様に、登場する主要ベンダーの種類もまた異なる、ということになる。
※2 「RPA国内利用動向調査 2021」(2021年1月時点)、MM総研、2021年2月発表