
2020年は、新型コロナの影響もあり、紙の書類をデジタル化するOCR (Optical Character Recognition:光学式文字認識)の需要が爆発的に増えた年であった。実は新型コロナの影響が出始める前の2020年3月頭にミック経済研究所より発表されたOCR市場の予想※では、すでに2020年度の大幅拡大の予想が出ていた。
新型コロナ禍になり、OCR市場はさらに注目されているようだ。この記事は、いまホットになっているOCR市場について、その歴史を振り替えながらトレンドを見て行くことにする。
OCRの歴史をカンタン解説!
実は意外と古いOCRの歴史~1910年代から研究が始まる
OCRの歴史は意外と古く、約100年前から研究が始まっている。光電管を使ったスキャナ装置は19世紀末に発明されており、機械に取り込まれた文字イメージを、電信技術の拡張と視覚障害者が文字を読むための支援に活用しようと1910年~1930年代にかけて研究されたのがOCRの原点であったという。
最初の商用システムができたのは1955年で、雑誌社の販売報告書をコンピュータに入力したり、石油会社がクレジットカードの文字を読み取るのにつかわれた。1960年代後半になると、各国の郵便局が専用のフォント (OCR-A)やバーコードなどと一緒にOCR技術を使い、郵便物仕訳の効率化を始めた。この頃からOCRの技術が急速に発展し始めた。第一世代は決められたフォントの形で書かれた限定された文字セット (数字、記号など)のみ読み込むことができたが、数字、少数の英文字、記号については手書きにも対応した第二世代も同じ時期に登場した。
郵便から始まった日本のOCR~1960年代
日本でも1968年に郵便番号が導入されると、郵便番号の枠に手書きで書かれた数字を読み取り仕訳に活用されたのが、光学文字認識技術が実用的に導入された始まりとされる。東芝、日立、日本電気、富士通などの日本のベンダーもOCR市場に参入した。1970年代になると、手書きの英数字とカタカナも読めるものが登場した。
その後、1980年代にかけて第三世代のOCRエンジンが開発され、低品質活字、様々なフォントの種類やそれが混合で使われている場合 (マルチフォント) への対応、等幅フォントでない場合への対応など、レイアウト解析エンジンも登場し、改良が行われていった。
パソコンの普及で一般にもOCRが普及~1995年
コンピュータの主流がメインフレームからミニコン、さらにはパソコンに移るにつれて、ハードウェアが安価になり、OCRも1980年代からパッケージソフトとしてリリースされはじめ、徐々に一般ユーザーの手にも届くようになってきた。また、日本語対応は高品質活字であれば漢字も認識できるようになってきた。
そして、1995年にWindows 95がリリースされてパソコンが一般に広く使われるようになると、1990年代後半には安価なOCRのパッケージソフトがWindows上で利用できるようになった。ABBYYやScansoftが高精度で多言語に対応したOCRソフトウェアをリリースし、日本のベンダーも読取革命、読んde!!ココなど、日本語OCRエンジンは独自開発しつつ、英数字はABBYYのOEM提供を受けるなどしてパッケージをリリースしている。
また、1980年代にHPが開発した多言語対応のOCRエンジンTesseractが2005年にはGoogleのスポンサーの元オープンソース化し、いろいろなシステムに組み込まれ始めた。
クラウドとハードウェアの成熟で始まったディープラーニングブーム~2015年
2000年代後半から2010年代になると、大手クラウドベンダーがクラウドプラットフォームを整備しはじめ、コンピューティングリソースが飛躍的に安価に使えるようになり、複雑なニューラルネットワークの計算が必要なディープラーニング (深層学習)の研究が飛躍的に進みだした。
この頃になると文字の読み取り技術でもディープラーニングを使った研究が成果を上げて注目されだすなど、OCR技術へのディープラーニングの適用が盛んになった。2015年には画像認識の研究コンテストでニューラルネットワークの層数を飛躍的に増やしたモデルが好成績を収め、クラウド上でディープラーニング計算用のチップが搭載された仮想マシンを使った商用モデルの提供がいくつかのベンダーによって開始された。
AI-OCRという単語の登場とRPAとの連携~2017年
日本でも、深層学習の技術を使ってクラウド上で日本語手書き認識や、さまざまなレイアウトの文書のフィールドの意味を解釈しながら読み取りを高精度で行うOCRエンジンを提供するAI inside (DX Suite)、コージェントラボ (Tegaki)といったベンダーが日本市場でサービスを開始した。2017年頃から、従来のOCRエンジンと差別化を図るうえで、「AI-OCR」という単語が使われるようになった。実はこれは日本市場だけの言葉であり、他国では通用しない。また、厳密に言うと従来のOCRエンジンでもAIの技術は使われているので、厳密に言うと「AI-OCR」という分類は正しくないのであるが、「クラウド上のディープラーニングを活用したOCRエンジン」というところだろう。
また、OCRは紙の上の文字を装置で読み込んだ画像をエンジンにかけてデジタルデータ化して、それを活用するシステムに送る必要がある、という性質上、2017年頃からやはり流行り始めたRPAととても相性が良い。人間の業務を代わりにやることを考える場合、OCRは人間の「目」、RPAは「手」に相当する。「目」と「手」がうまく連携することで、一連の業務の流れをコンピュータで置き換えることが可能になる。どちらか片方だけでは適用可能な業務や自動化の範囲が限られてしまうため、AI-OCRとRPAを一緒に連携させて導入することで、適用範囲、自動化の範囲が広がるのである。
日本語の手書き認識や非定型帳票に強みを持つAI-OCRが人気
調査会社のミック経済研究所では、従来のOCR (汎用OCR)とAI-OCRの分類を以下のように行っている※。(この分類はあくまでも便宜的なものであることは前述の通りである)
| カテゴリー | 汎用OCR | AI-OCR |
| 非定型帳票の認識* | 非対応 | 対応可能 |
| 文字認識方法 | ベクトル、確率分布等 | AI: ディープラーニング |
| ノイズ処理 | 従来方式 (非AI) | AI: ノイズ処理エンジン |
| 誤認識の修正 | 辞書登録 | AI: 自然言語処理 |
| 利用形態 | オンプレミス | クラウド |
* 文字枠なし、自由記入欄の体裁による非定型書類を指す。
現在の日本市場では、AI-OCRベンダーは20種類前後がリストされている。AI-OCRの市場は2019年度に延びはじめ、2020年度には大きく伸びることが予想されている。(さらに、新型コロナの影響で、この伸びが加速されることが予想される) そして、今後はAI-OCRの市場が急速に伸びていき、2022年度には、汎用OCR市場と市場規模が逆転すると予測されている。
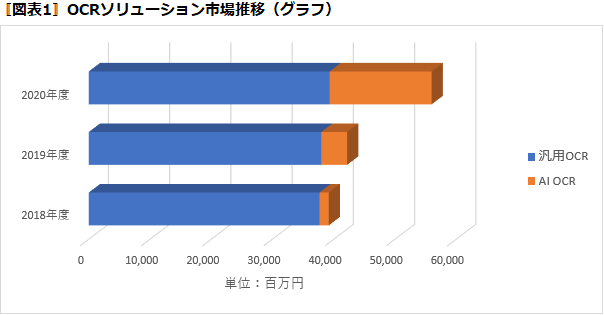
※出典:ミック経済研究所
ベンダー間のシェアのデータは、AI insideは契約数が2020年9月末時点で12,700件以上※※、64%のシェアを持っているとされている※。
ちなみに、この分類では、特定の文書の読み取りに限らない “汎用的な” OCRを念頭に置いている。名刺やレシートといった特定の文書については、より高精度で読み取ることができる専用のソリューションが別途存在する。
このように、最近の傾向としては、クラウド上のディープラーニングを活用して、日本語の手書きや非定型帳票に強みを持つOCRエンジンが選ばれている。
AI-OCRはサブスクリプション形式であることに注意
留意点としては、AI-OCRソリューションは今までの汎用的なOCRに比べるとまだ高価なものが多く、かつパッケージソフトのように買い切り型ではなく、サブスクリプション形式であることだ。AI-OCRは基本、クラウドを活用しているため、クラウドがサブスクリプション形式の課金である以上、サブスクリプションの形を取るものがほとんどである。
2021年のAI-OCRのトレンドはどうなる?
さて、2020年度はかなりの躍進があったAI-OCRであるが、2021年はどうなるのであろうか。引き続きリモートワークや働き方の変革が求められ、政府も業務プロセスや印鑑のデジタル化を推進しているため、業務が完全なデジタルに移るまでの過渡期として、OCRは引き続きニーズが高いソリューションであり続けると思われる。
さらに、2021年は2020年度から始まっているいくつかのことが広く展開されていくことになると思われる。
展開オプションが増え、より多くの業務に適用される
AI-OCRはさきほど「クラウド上で…」という話をしたが、適用範囲が広がってくるとユーザーのいろいろなリクエストに対応する必要が出てくる。初期に採用するユーザーは「クラウドでも問題ない」というユーザーが中心であったが、クラウドによる展開は一般的になってきたとはいえ、まだオンプレミス型を要望するユーザーも多く、特に金融・製薬・医療などの規制業種や、官公庁・地方自治体はオンプレミス型のみになるため、オンプレミスへの対応が必要になってくる。
AI-OCRベンダーの中には、クラウド上で実装しているニューラルネットワークのミニチュア版をオンプレミスのハードウェアに実装してアプライアンスの形で提供し始めているところもある。クラウドも、その機能のミニチュア版をオンプレミスで提供するエッジコンピューティングの選択肢が出てきているが、OCRもまさに同様の形式が選択できるようになりつつある。
また、地方自治体向けにはLGWANとつながるクラウドで提供する形態を提供しているAI-OCRベンダーも出てきている。AI-OCRの読み取り精度は進化の途中であり、クラウドで提供することで、ディープラーニングのモデルを常に最新のものに保っておけるため、「半年前に読めなかった文書がいまは読めるようになった」というような進化もあり得るが、オンプレミスにするとその時点でモデルが固定され、精度は向上しないという欠点がある。LGWANに向けたクラウドになっていれば、限定的ではあるが読み取り精度を向上させながら地方自治体での活用が可能となる。2021年は、展開オプションが増えることによって、より適用できる業種、業務が増えるだろう。
複数のOCRエンジンを搭載するソリューションが増える
もう一つの動きとして、複数のOCRエンジンやレイアウト解析エンジンを搭載した複合OCRソリューションが今後伸びていく可能性がある。OCRエンジンやレイアウト解析エンジンにはそれぞれ得意不得意分野があり、すべての文書で万能に使えるエンジンは存在しない。扱う文書のレイアウトや内容によって、OCRエンジンやレイアウト解析エンジンを使い分ける方が文字認識精度は向上する傾向にある。極端な例が、名刺やレシートなどの特定の文書に特化したOCRエンジンだ。これらは特定のシナリオに特化する分、そのシナリオでの認識精度が最高になるように最適化を行っている。
より汎用的な文書を扱うOCRソリューションでは、扱う文書によって違う性質のOCRエンジンの中から最適なものを都度選択できた方が、認識精度を最適化できる。また、複数のOCRエンジンで同じ文書を認識させてダブルチェックを行う「再鑑」と呼ばれる手法も取ることができる。
実際に複数のOCRエンジンを搭載しているソリューションには以下のソリューションがある。
- Automation Anywhere IQ Bot: ABBYY、Tesseract、Azure Computer Vision、Google Vision、コージェントラボ Tegakiの5種類から選択可能。
- ウイングアーク1st SPA: ABBY、WinArc Data Capture、コージェントラボ Tegaki、DEEPREADの4種類から選択可能。
- キヤノンITS CaptureBrain: 独自エンジン、コージェントラボ Tegakiから選択可能。
また、BPO (ビジネス・プロセス・アウトソーシング)の形で利用するOCRソリューション、いくつかのOCRエンジンを裏でソリューションプロバイダーが選択して認識精度のチューニングをしていくサービスもさまざま出ている。たとえばコニカミノルタ Robotics BPOなどである。
まとめ
以上見てきたように、OCRエンジン自体はコンピューティング能力の向上によるディープラーニングの力を使った認識精度向上に加えて、提供形態の多様化、複数OCRエンジンの利用による精度アップなど、中核技術、周辺技術、統合ソリューションの各レベルで近年大きく進化をしてきているのがOCRソリューションである。2021年は市場のニーズもけん引して、OCRソリューションが広く採用される年になるかもしれない。
※『AI OCRで拡大するOCRソリューションの市場動向 2020年度版』2020年3月、ミック経済研究所。元となる調査は2019年12月~2020年2月にかけて行われている
※※ベンダー発表の情報。
