
2020年は新型コロナ禍においてペーパーレス化のニーズが劇的に高まった。紙に書かれている情報をデジタル情報に変換する光学文字認識 (OCR: Optical Character Recognition)の需要が急増している。技術的にも、従来の純粋に文字を読むOCRの技術に人工知能 (AI) による認識機能を加えたAI-OCRによるアプローチを取ることで、認識精度も従来よりも劇的に向上してきた。
AI-OCRのプロジェクトは一般的に、まず概念検証(PoC)を行い、業務への適合性を確認した上で本格導入へと至るケースが多い。そんなPoCを100社近く行ってきたのが、オートメーション・エニウェア・ジャパンのセールスエンジニア佐野千紘氏だ。多くの企業の成功と失敗を見てきた佐野氏に、AI-OCRプロジェクト成功の秘訣を聞いた。
Contents
AI-OCRが文字を読み取るいくつかの方式と技術
AI-OCRの二大機能とは
「AI-OCRには二大機能があります。一つ目は『文字を読む』こと、つまり画像の特定の部分をテキスト情報に変換することです。二つ目は、『文字情報を適切なデータ項目に紐づけること』、つまり特定の場所にあるテキスト情報をデータ項目と紐づけて正しいフィールドに格納することです。一つ目は明らかですが、二つ目は見過ごされがちです。」(佐野氏)
AI-OCRの多くは単なる文字認識だけでなく、書式からテキストの意味付けをするところまで担っている。そして、文字の認識以外の機能や精度も、全体のパフォーマンスに大きく影響することになる。
「二つ目の機能、つまり文字情報とデータ項目の紐づけには、主に2つの手法があります。『座標指定型』と『自動検出型』の手法です。それぞれメリットとデメリットがあり、対象となる帳票の性質や種類に適したものを見極めることが重要です。」(佐野氏)
文字情報をデータ項目と紐づける2つの手法

それぞれの手法をまとめると以下のようになる。
1.座標指定型: 帳票上のどこから文字を読み取るべきかをユーザーがあらかじめ指定し、OCRは選択された座標の場所から文字を読み取るという手法。位置が正しく指定できている限り、高い精度が出やすい点がメリットである。固定帳票やごくシンプルな準定型帳票のみがターゲットであれば、座標指定型が馴染みやすいだろう。
注意点として挙げられるのは、スキャン時のずれなどにより少しでも位置がずれると読み取りの結果が変わってしまう場合があることだ。
読み取り位置のずれは、紙をスキャンする時の状態によって発生することがある。上下左右の座標のずれ、ゆがみ、書類の角度、などである。たとえば『音目太郎』という文字が少し下にずれて上半分だけが読み取り座標にかかっている場合は、『立日大白13』と認識されてしまうといったことが起こり得る。
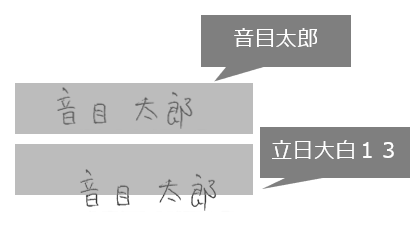
また、複雑度の高い準定型帳票(表の行数が可変、ページ数や項目の位置が帳票によって変わる場合があるなど)を座標指定型で処理しようとすると、精度が著しく下がったり、処理不可となるケースもある。
2.自動検出型: 帳票全体を読み込ませることで、OCRが文字を自動検出する手法。帳票全体からの文字の検出と読み取りをいずれも自動で行うため、狭い項目欄を決め打ちで文字認識する座標指定型に比べると精度は低く出やすいが、少し位置がずれても読み取り結果が安定する点はメリット。加えて、可変の明細や浮動項目の読み取りをするためには必須の手法となる。ただし、パターンの認識をさせるために大量の帳票サンプルが必要となることが多い。
座標指定型、事前学習型の手法を使ったAI-OCRのソリューションは、それぞれ事前設定の方法が異なってくる。表にまとめてみると以下のとおりとなる。
| OCRソリューションの型 | 座標指定型 | 事前学習型 |
| 基本的な考え方 | テンプレートを登録し、テンプレートごとに取得したい項目の位置(座標)を指定 | 大量の帳票サンプルをAIに読み込ませ、取得項目の位置を推論 |
| 文字認識 | 指定された場所から (座標指定) | 自動検出 |
| データ項目との紐づけ | テンプレート上の位置によって項目が決まる | AIが読み込んだ大量のサンプルから紐づけを推論 |
| 得意な帳票 | 固定帳票、シンプルな準定型 | 固定帳票、多岐にわたる準定型帳票 |
| メリット | 位置指定が正しくできれば高い精度が出せる | テンプレート型では対応しきれない複雑な明細を取得できる |
| デメリット | 複雑な明細の抽出には向かない、スキャン時のずれで精度が大きく下がる | 事前設定にかかる時間とコストが莫大。サンプルが大量に必要。データサイエンティストなどの専門家が必要。コストが3~4倍になることも。 |
どれをとっても、「あらゆる帳票に完璧に対応できるOCR」は存在しない。OCRの製品を探し始める前に、あるいは探すのと並行して、自分たちがOCRを使って何をしたいのかを明確にし、ニーズに合ったソリューションを選択することが大切だ。
オートメーション・エニウェアの「IQ Bot」は座標指定型と事前学習型のハイブリッド
これらを踏まえたうえで、佐野氏はオートメーション・エニウェアで提供しているAI-OCRのソリューション『IQ Bot』について、その仕組みの概要を解説する。
「文字の認識の仕方は自動検出です。データ項目との紐づけは、ラベルと値の相対的位置関係で推論をしています。これにより、テンプレート型で対応できない複雑な明細も取得可能であり、かつ通常の事前学習型より少ないコストで事前設定を可能としています。」(佐野氏)
「IQ Botであれば可変明細行数、ページ跨ぎの明細行も取得可能です。座標指定型のOCRを試したものの、このあたりの処理ができなかったゆえにIQ Botにたどり着いたというお客様は非常に多いです。また、ひとつの明細行の中に場合によって2行のテキストが含まれている場合や、送料などのフィールドが何ページ目に来るかがわからない場合などもIQ Botであれば取得することが可能です。」(佐野氏)
AI-OCRの導入を検討している企業がPoCに入る前に考えておきたいこと
IQ Botに限らず各社が出しているAI-OCRソリューションを導入する際には、あらかじめユーザー企業側で注意しておくことがあるという。大きく2つの点があるので順に見て行こう。
取り組む前に本当にAI-OCRが最適解かをまず考えよう
「いままで100社近いPoCを実施して来ました。振り返ってみると、本当にそれOCRにやるんですか、という要件も中にはありました。」と佐野氏は振り返る。ユーザー企業も「紙業務の効率化=AI-OCRで解決」という単純な思考になっていることが多い。しかし、AI-OCRは決して万能なソリューションではない。適用しようとしている業務の効率化をAI-OCRで実施するのが最適解なのかをまず問う必要があるという。
「AI-OCRの対象となる書類 (帳票) には大まかに『定型(固定)帳票』『準定型帳票』『非定型帳票』の3種類が存在します。対象とする書類がどれに当てはまるかにより、AI-OCRを使うべきかが決まってきます。」(佐野氏)
3つの分類を簡単にまとめると以下の通りとなる。
- 固定帳票: 一番簡単。帳票ごとに書式が一つに決まる。申込書、診断書などが例。座標指定型OCRでも比較的容易に実現可能。自社で書式を決められることも多いため、デジタルフォームで代用できる場合もある。
- 準定型帳票: 同種の帳票の中に複数の書式。いくつかのパターンに集約可能。項目の位置やラベルにある程度の規則性がある。請求書、注文書などが例。書式の多さによって座標指定型か自動検出型のいずれかを選択する。例えば種類が3種類しかないなら座標指定型でもよい、など。自動検出型で対応する場合は、投資に見合う効果が出るかどうかを検討する必要あり。特化型アプリがあればそちらの方が良い場合も。
- 非定型帳票: 帳票ひとつひとつが完全にバラバラで、書式、項目の位置や規則性やラベルが存在しない、ほぼ文章になっている形式。メール本文、機械の設計図面など。文章から日付などを抜き出す場合、OCRと合わせてNER (固有表現認識)など、他領域のAI技術が必要。
固定帳票の場合は、自社で書式を決められる場合も多い。その場合、最初から手書きでなくWebフォームなどのデジタル技術を使う方がうまくいく場合もあるという。申込書、アンケートなどがそれにあたる。特に、アンケートは回収枚数が多くない割に設定が大変になるので、AI-OCRの対象としてはお勧めしないと佐野氏は言う。ただし、高齢者が答える必要がある場合、回収率低下を懸念する場合などもあるため、メリット、デメリットをよく天秤にかけて検討する必要がある場合も出てくるだろう。
「準定型帳票の場合は、レシート、名刺、住民票、免許証など特定の帳票に対しては特化型アプリが存在しており、認識精度を特別に調整して高精度で読めるようになっています。汎用的なAI-OCRソリューションを使って作り込むよりも、そちらを活用することをお勧めするケースもあります。」(佐野氏) 特化型アプリがあり、そのアプリが抽出対象になっているデータが欲しい場合は、そのアプリを導入することをまず検討したほうが良いという。
このように、紙業務の自動化・効率化を行うにあたりAI-OCRを導入することが正解とは限らない。広い視野で最適なソリューションを選ぶことが大事であると佐野氏は強調した。
OCRの精度は100%でないことを前提に業務プロセス設計が必要

もう一つ注意すべき点として、認識精度との正しい向き合い方をあらかじめ考えておく必要があるという。これを間違うと、OCRプロジェクトがPoCで止まる原因にもなるというのだ。
「そもそもAI-OCRの認識精度は100%はあり得ないです。」と佐野氏は言う。製品によっては、Webページやカタログ等で非常に高い認識精度を売りにしている場合があるが、ベンダー公称値は保証値ではないことに注意が必要である。「ベンダーの公称値は99%だったものの、自分たちの帳票で試してみたら70%にも満たなかった、というお客様も過去にいらっしゃいました。ベンダーの公称値はあくまでもベンダーが用意したサンプルで、読み取り位置の指定が正しい前提でテストをした結果であり、このあたりが実際の運用とズレが出てくる要因になっています。」(佐野)
そもそも認識精度の高さが運用後の事務効率に比例するわけではない、と佐野氏は言う。「AI-OCRの導入により事務効率が高くなるかどうかは、AI-OCRがどのようなプロセスの中でどう使われているかに依存します。5%~10%くらいの精度の違いがあっても、自社内で業務フローを作りやすい製品のほうが結果的に効率が上がることも多いです。」
たとえばOCRで99%の精度が出たとしても、残りの1%の誤りを検知するために全件人が目で見る、というフローを組むことを考えてみよう。たとえ1%を検知するためであっても、結局全件人が見るのであれば、検知される誤りが1%から3%、5%と増えたとしても、全体効率はさほど変わらない。
それよりも、「誤りを発見した場合に修正がしやすいか」「誤っている可能性があるものを効果的に見つけ出し、それ以外は自動処理にできるか」といった視点で考えた方が、業務全体としては効率が上がりやすい。
「千枚の帳票を処理する場合、OCRの精度が99%でも、100%目検証が必要なフローであれば、人が千枚の帳票を目で見て、千回確認するというプロセスが必要になります。OCRの精度は95%でも、誤りを含む5%を確実に検知することができれば、正しくとれた95%は自動処理に回すことができます。これなら、人が確認するのは50枚で済みます。精度≠業務効率、というのはそういう意味です。」(佐野)
AI-OCRの認識精度は100%にならないことを前提に、誤りをいかに適切に検知しながら自動化率を高めていくかを考えるほうが生産的であり、OCRを実用的に活用しやすいという。
誤り検知の条件が多彩に指定できることは、IQ Botの特長のひとつでもある。
「取得したテキストが日付、数字などの型にあった形式になっているかの検証も可能です。日付は和暦もOKです。型番、電話番号、メールアドレスなどの形式を正規表現で検知することもできます。都道府県名など、特定の選択肢のいずれかに完全一致しているかという検証もできます。」(佐野氏)
IQ Botでは、加えて数式による検算もできる。数量 x 単価が金額と一致しているか、税抜き価格+消費税が税込み価格と一致しているか、明細行の金額の合計が合計欄と一致しているか、など、柔軟な検知が可能となっており、RPAプラットフォーム『Automation Anywhere Enterprise A2019』に組み込まれていることの強みとなっている。
「IQ Botは直感的で使いやすく簡単に設定ができるようになっています。また、スキルが高いパワフルな開発者がいれば、Pythonで抽出したデータの加工などの高度な設定も可能です。」(佐野氏)
まとめ: スムーズな導入につながるケース、つながらないケースの違いは?
いままでの100社近い事例の経験を踏まえ、AI-OCRプロジェクトでうまくいくケースとうまくいかないケースの境目を佐野氏は2つのポイントにまとめた。
プロセスの明確化、プロセスのイメージがあらかじめ明確になっているか
後続処理、誤り検知の手段、人による修正を含めた自動処理のプロセスが明確になっていることが必要となる。ひとまずOCRでどこまで読めるか知りたいという課題認識にとどまっている場合、途中でプロジェクトが止まってしまいがちになる。精度をやみくもに上げようとするのではなく、どのようなプロセスが構築できるのであれば誤差を許容できるのか、という議論にシフトしていく必要がある。
読み取り対象項目の選定も重要
型番、顧客番号、電話番号、金額など、検算、書式などにより誤り検知が機械的に可能である項目であれば、高い精度で自動化が可能となる。
特記事項欄などの長文や契約書本文、商品名の名前を100%読めることが前提となっている場合、PoCを実施しても本導入には至りにくい。100%の精度が必要であれば人の検証を必ず通す、あるいは意味が解る程度に読めていればOKと割り切るなど、現実的な対応策をとれるかが成否の分かれ目となる。
まとめ:プロジェクトを進める際の推奨事項
最後に、佐野氏はAI-OCRのプロジェクトを始める際の推奨事項として、以下の3点に気を付けるべきと締めくくった。
- 紙を使っているからと言ってOCRで、と短絡的に考えず、目的に照らした最適解を選択すること。
- 対象とする帳票の性質に応じた製品選定をすること。
- 精度100%はあり得ないことを前提に、誤り検知の方法・自動処理率といった指標も考慮に入れながら、現実的な対応策を考えること。
